This weekend I decided to take the time to play with Microsoft Visual Studio. As a UF student I was able to download Microsoft Visual Studio Professional 2013 for free from onthehub.com, Microsoft’s Dream Spark portal. As a person who usually does most of their programming from command line Linux (vim + gcc) it was both convenient/a bit clunky working in an IDE.
Programming in Visual studio reminded me a lot of java programming in eclipse. While java is something that eclipse did well the c++ development environment wasn’t something to die for. This is something Visual Studio does well.
As my first project I decided to write a simple implementation of the hashmap data structure I don’t really have plans for using it in a future project but it was a good exercise. As most people know, the idea behind a hashmap is to map a value to a place in memory based off of a key. In my implementation the key is a string and the value is a void pointer. I used a void pointer because I wanted the structure to be as generic as possible.
Source code: https://github.com/quantumvm/c-hashmap
By including the header file, you can interact with a hashmap using three different functions:
1 2 3 | |
The create function initializes the hashmap, the put function adds a value to the hashmap, and the get function retrieves a value from the hashmap. The header file also describes two new types, a hash_map type which is a struct describing the hashmap and a hash_map_bucket, the later of which was necessary for the implementation rather than for the programmer.
A hashmap works on two pretty basic principles hashing and mapping. A hashing algorithm takes an input value and produces a unique uniform output. By taking the modulus of the hashmap we can map this unique hash map to a position in an array or bucket. This results in some pretty excellent O(1) time complexity.
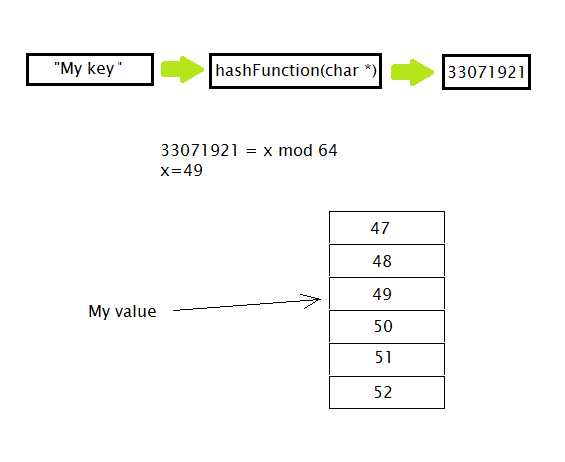
Although the majority of the time the hash look up succeeds, you do occasionally encounter a problem where two hashes will map to the same bucket. There are different ways to handle this but I decided the best way to take care of this would be to make the hash_map_bucket struct the basis for a singly linked list. If the initial look up fails, I can simply call a recursive function that tries to find the next hash_map_bucket in the struct. If this fails it is assumed that the key isn’t actually in the hashmap and a nullpointer is returned.
The problems I encountered when designing/testing the hashmap were rather minor. One issue was structs that had memory being allocated using malloc() were not necessarily being initialized to zero. This became an issue because when a pointer to a node was declared in the struct, there wasn’t a grantee that it was a null pointer. Some of the functions I wrote like getNextAvailableBucket() relied on traversing nodes until a null pointer was encountered. The solution to this problem was to use the function calloc() instead which turned out to have more relevant syntax and by default zeroed out the memory.
The other problems I encountered had more to do with the transition from gcc to visual studio’s compiler. Personally I had never used a precompiled header before so using: #include “stdafx.h” Was rather new to me. One solution was to just start an empty project but I decided to work with the precompiled header anyway.