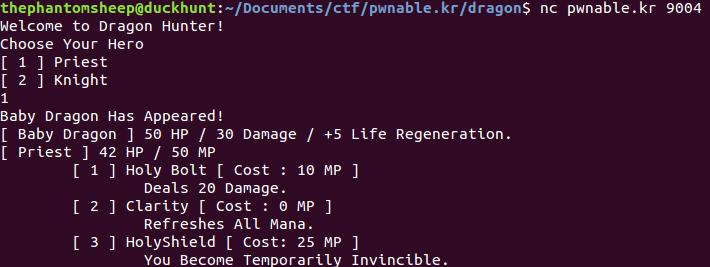
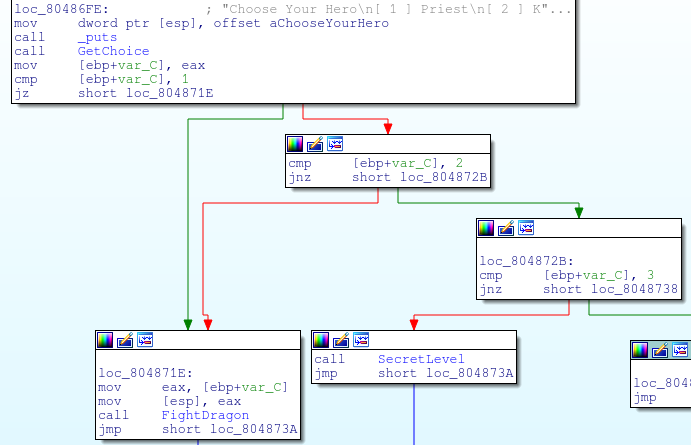
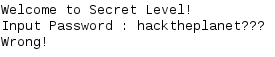
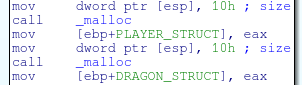
UF-SIT, UF’s cyber security club, is holding lightning talks on the 17th of Novemeber! I’ve decided that an awesome way to peek people’s interest in reverse engineering and exploitation is to give a talk on format string vulnerabilities. This talk is aimed at people that really want to learn more, but are stuck doing basic stack-based buffer overflows.
To understand format string exploits, first you need a program that can be exploited. I decided to write a program that should be easily exploitable on Ubuntu 14.04 with all of the standard flags for gcc left enabled.
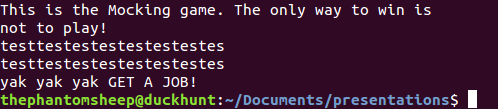
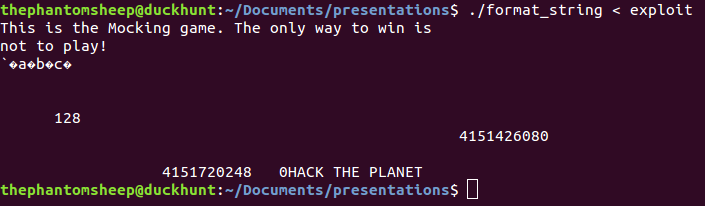
It’s a mocking game! It simply repeats back whatever string it receives. Let’s take a look at the source code of the program to see if we can come up with an idea on how to exploit it.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | |
The vulnerability occurs because the user can control the format string passed to printf:
1
| |
This vulnerability could be easily fixed by using the printf function appropriately!:
1
| |
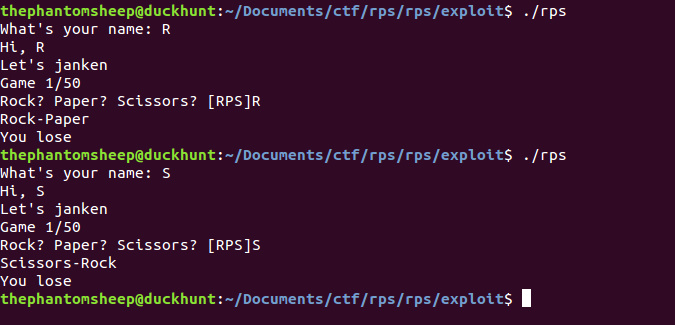
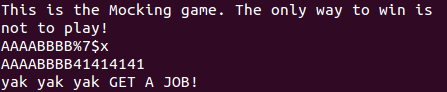
It’s a very subtle difference, but watch what happens when we enter some input that the programmer was not expecting like the character percent followed by the character x.

We’ve started to leak information from the stack! In fact we’ve leaked so much information that we’ve reached the area on the stack where our format string was stored! Just for clarity the format string is the first line with (AAAABBBBCC..). Let’s stop a moment to see why this happens.
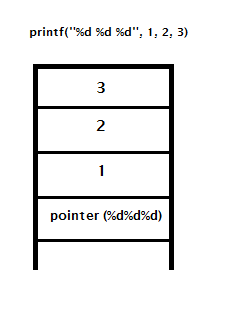
On x86, when a function is called using CDECL calling conventions, its parameters are pushed on the stack in reverse order as seen above. When printf wants to use parameter 2, the second percent d, it reaches all the way up the stack to 2 or (esp + 8). When we control these percent d, like in our vulnerable program, we can read as far up the stack as we want!
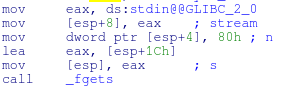
When we look at this assembly language in IDA, fgets is storing the format string itself at esp+1C (esp+28) This means that by going as far as 7 percent xs we can start reaching data we can control!
Printf even has a useful feature called direct parameter access that allows us to skip placing percent x over and over again and just reference a value from its relative location on the stack!
I am sure it has an “actual” application outside of exploitation, but let’s be honest that’s pretty darn convenient.
All we’ve done now is READ data data from the stack. Maybe that’s useful for a memory leak but how can we use the printf function to control the flow of our application? Surprisingly printf actually allows us to WRITE data to the stack using the percent n parameter. Yep.
Percent n allows the user to write the total number of bytes that will be printed by printf up to the point where the format string is encountered. The amount of information percent n writes is 4 bytes on x86. Let’s figure out what address we have to write and where we have to write it.
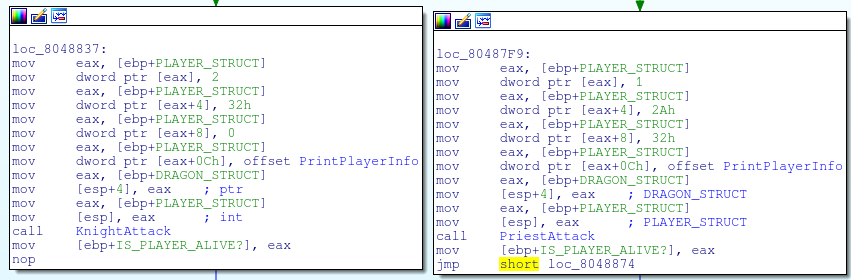
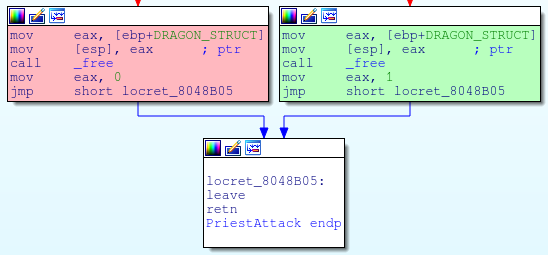
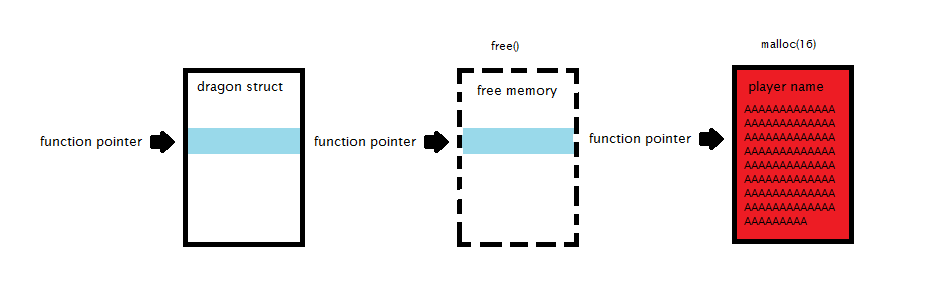
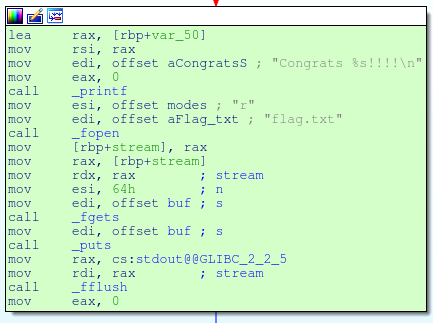
The easiest way to break the program is to overwrite the function pointer found in the foobar struct.
1 2 3 4 | |
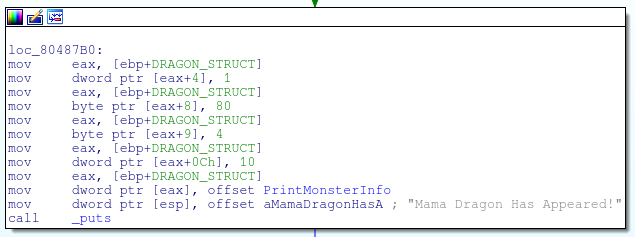
Later on in the program, we see that an instance of the struct, called test, is initialized in the bss segment right above main. Let’s find this struct in memory using IDA.

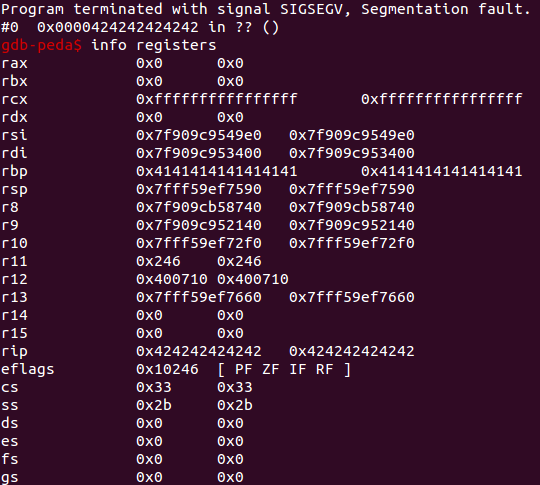
When we look at this memory in debug mode we see that the address of the lose function (picture below) is written to this address.

The address is written into memory using little endian byte order.

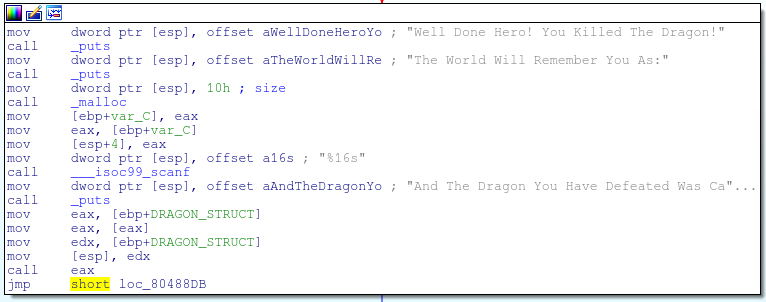
We want to change this address stored at 0804A060 to the address of our win function (picture below)

An obvious issue that we encounter is that the address 0x08048501 = 134513921. To use our percent-n method we would have to have printf print almost 134 megabytes worth of junk! That’s a rather huge amount of writing. Let’s exploit the fact we are using little endian byte order! We can perform 4 writes instead of 1 write. The picture below provides an illustration of what our final exploit will look like.

To calculate the “value to write” for the percent u we can use a simple function that increments our total byte counter until the lowest byte is equal to the byte we want to write. We can then return the total number of bytes we have to add to our format string to get there.
1 2 3 4 5 6 7 8 | |
Here is the rest of our exploit that prints our targeted format string to stdout.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | |
This is what our exploit will look like when printed to standard out:

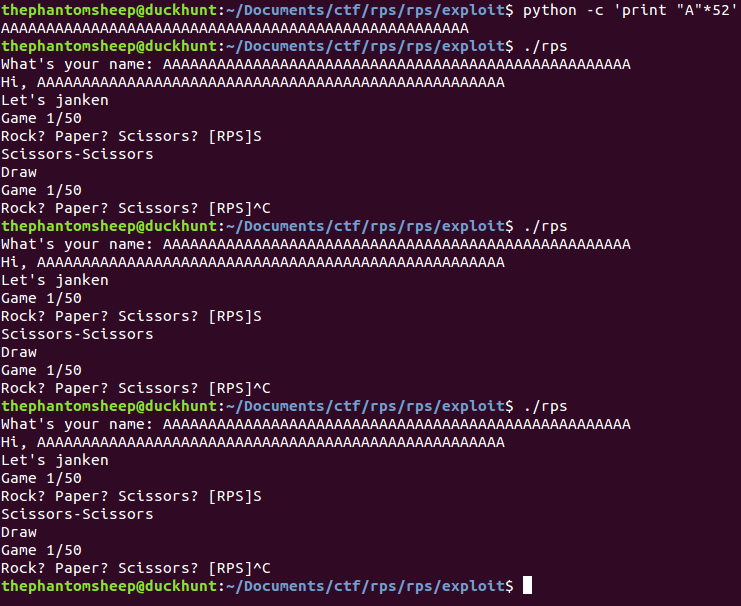
Let’s see what happens when we shove the exploit into our mocking game program!

HACK THE PLANET! We win!